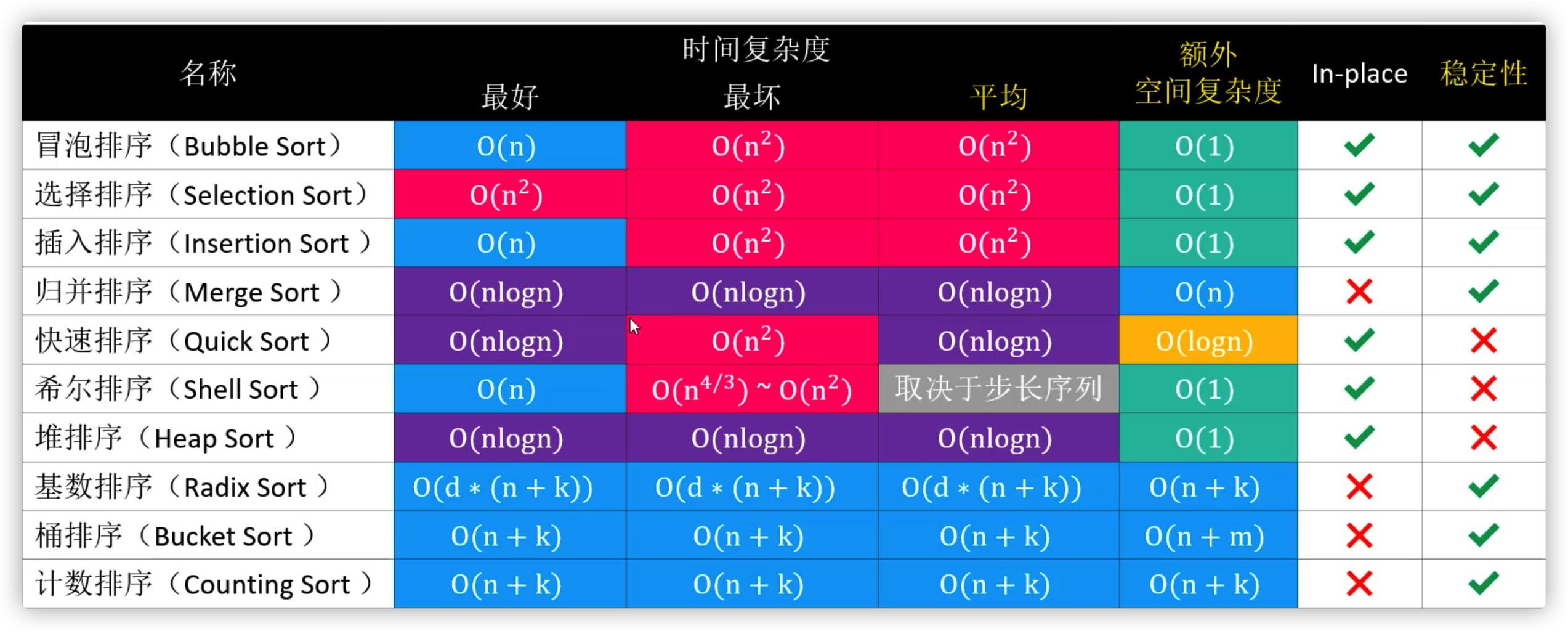
首先认识一下十大排序算法
冒泡,选择,插入,归并,快排,希尔,堆排序属于比较排序
准备工作 在开始介绍排序算法之前,首先先设计一下接口,方便进行性能测试和验证正确性。
这里使用Java中的抽象类来统一接口,留出抽象sort方法给子类实现。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 protected Integer[] array;private int cmpCount = 0 ;private int swapCount = 0 ;private long time;private DecimalFormat fmt = new DecimalFormat("#.00" );protected abstract void sort () public void sort (Integer[] array) if (array == null || array.length < 2 ) {return ;this .array = array;protected int cmp (int a, int b) return array[a] - array[b];protected int cmpElement (Integer a, Integer b) return a.compareTo(b);protected void swap (int a, int b) int temp = array[a];private String numberString (int number) if (number < 10000 ) {return "" + number;if (number < 100000000 ) {return fmt.format(number / 10000.0 ) + "万" ;return fmt.format(number / 100000000.0 ) + "亿" ;@Override public String toString () "耗时:" + (time / 1000.0 ) + "s(" + time + "ms)" ;"比较:" + numberString(cmpCount);"交换:" + numberString(swapCount);return "【" + getClass().getSimpleName() + "】\n" " \t" "\t " "\n" "------------------------------------------------------------------" ;@Override public int compareTo (Sort o) int result = (int ) (this .time - o.time);if (result != 0 ) {return result;this .cmpCount - o.cmpCount;if (result != 0 ) {return result;return this .swapCount - o.swapCount;
基于比较的排序
让我们从最简单的冒泡排序开始
冒泡排序
遍历相邻两位,根据比较规则决定是否交换
每次遍历都会完成一位排序,因此下次开始时可以后移一位进行比较
遍历数组长度-1次之后排序完成
显然如果一次遍历没有交换代表排序已经完成,这时可以提前结束循环
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public class BubbleSort extends Sort @Override protected void sort () for (int i = 0 ; i < array.length - 1 ; i++) {boolean flag = true ;for (int j = i; j < array.length; j++) {if (cmp(i,j)>0 ) {int temp = array[i];false ;if (flag) {break ;
最好
最坏
平均
额外空间复杂度
In-place
稳定性
O(n)
O(n^2)
O(n^2)
O(1)
√
√
排序算法的稳定性
这里引入排序算法的稳定性这个概念
如果相等的2个元素,在排序前后的相对位置保持不变,那么这是稳定的排序算法
排序前: 5 , 1 , 3 𝑎 , 4 , 7 , 3𝑏
稳定的排序: 1 , 3 𝑎 , 3 𝑏 , 4 , 5 , 7
不稳定的排序:1 , 3 𝑏 , 3 𝑎 , 4, 5 , 7
对自定义对象进行排序时,稳定性会影响最终的排序效果
冒泡排序属于稳定的排序算法
稍有不慎,稳定的排序算法也能被写成不稳定的排序算法,比如下面的冒泡排序代码是不稳定的
1 2 3 4 5 6 7 for (int end = array.length-1 ;end > 0 ; end--){for (int begin = 1 ; begin<end; brgin++){if (cmp(begin,begin-1 )>=0 ){1 );
原地算法
何为原地算法?
不依赖额外的资源或者依赖少数的额外资源,仅依靠输出来覆盖输入
空间复杂度为 𝑂 ( 1 ) 可以认为是原地算法
非原地算法,称为 Not-in-place 或者 Out-of-place
冒泡排序属于 In-place
选择排序
外层循环收缩区间
内存循环遍历当前区间
每次遍历选择当前区间最大元素与最后元素换位
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class SelectionSort extends Sort @Override protected void sort () for (int end = array.length - 1 ; end > 0 ; end--) {int maxIndex = 0 ;for (int begin = 1 ; begin <= end; begin++) {if (cmp(maxIndex, begin) < 0 ) {
最好
最坏
平均
额外空间复杂度
In-place
稳定性
O(n^2)
O(n^2)
O(n^2)
O(1)
√
√
选择排序的选最大值部分经过优化后就引出了堆排序
堆排序
就地创建一个大顶堆
根据大顶堆的性质,最大元素在array[0],所以每次循环交换首尾元素,同时堆的大小减1,恢复堆的性质
当堆的大小为1时就完成了排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class HeapSort extends Sort private int heapSize;@Override protected void sort () for (int i = (heapSize >> 1 ) - 1 ; i >= 0 ; i--) {while (heapSize > 1 ) {0 , --heapSize);0 );private void siftDown (int index) int half = heapSize >> 1 ;while (index < half) {int childIndex = (index << 1 ) + 1 ;int rChildIndex = childIndex + 1 ;if (rChildIndex < heapSize &&0 if (cmpElement(element, child) > 0 ) {break ;
最好
最坏
平均
额外空间复杂度
In-place
稳定性
O(nlogn)
O(nlogn)
O(nlogn)
O(1)
√
×
插入排序
从数组下标1开始依次选择数组元素与前一个元素比较
如果当前位置无序,就与前一个元素交换位置,直到有序
1 2 3 4 5 6 7 8 9 10 11 12 13 public class InsertSort <E extends Comparable <E >> extends Sort <E > @Override protected void sort () for (int begin = 1 ; begin < array.length; begin++) {int cur = begin;while (cur > 0 && cmp(cur, cur - 1 ) < 0 ) {1 );
最好
最坏
平均
额外空间复杂度
In-place
稳定性
O(n)
O(n^2)
O(n^2)
O(1)
√
√
关于插入排序需要了解一个概念
逆序对
什么是逆序对?
数组 <2,3,8,6,1> 的逆序对为:<2,1> <3,1> <8,1> <8,6> <6,1>,共5个逆序对
插入排序的时间复杂度与逆序对的数量成正比关系,逆序对的数量越多,插入排序的时间复杂度越高
当逆序对的数量极少时,插入排序的效率特别高,甚至速度比 O(nlog n )级别的快速排序还要快
数据量不是特别大的时候,插入排序的效率也是非常好的
对于交换元素可以进行小小的优化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class InsertSort <E extends Comparable <E >> extends Sort <E > @Override protected void sort () for (int begin = 1 ; begin < array.length; begin++) {int cur = begin;while (cur > 0 && cmpElement(e, array[cur-1 ]) < 0 ) {1 ];
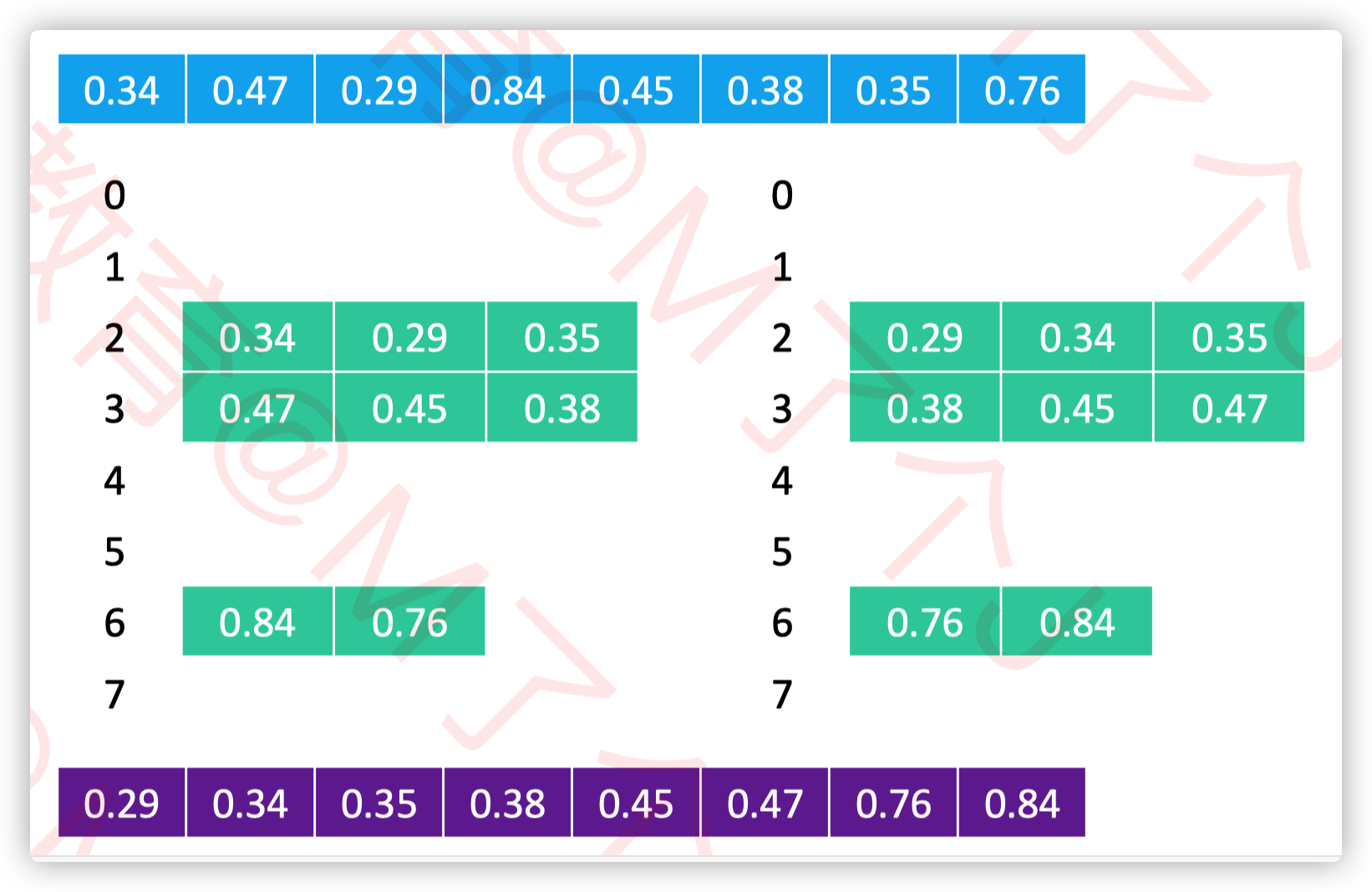
对于插入排序,找出插入位置的算法还可以进一步优化,我们先了解一下二分搜索
二分搜索 如何确定一个元素在数组中的位置?(假设数组里面全都是整数) 如果是无序数组,从第 0 个位置开始遍历搜索,平均时间复杂度:O(n)
0
1
2
3
4
5
6
7
8
9
31
66
17
15
28
20
59
88
45
56
如果是有序数组,可以使用二分搜索,最坏时间复杂度: O ( lo g n )
0
1
2
3
4
5
6
7
8
9
15
17
20
28
31
45
56
59
66
88
假设在 [begin, end) 范围内搜索某个元素 v,
mid == (begin + end) / 2
如果 v < m,去 [begin, mid) 范围内二分搜索
如果 v > m,去 [mid + 1, end) 范围内二分搜索
如果 v == m,直接返回 mid
由此可以得出一个用二分搜索确定插入位置的算法
优化过的插入排序 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Override protected void sort () for (int begin = 1 ; begin < array.length; begin++) {private void insert (int begin, int dest) int cur = begin;while (cur != dest) {1 ];private int search (int index) int begin = 0 ;int end = index;while (begin < end) {int mid = (begin + end) >> 1 ;if (cmp(array[mid], e) > 0 ) {else {1 ;return begin;
尽管优化过了插入时的搜索,但时间复杂度仍然是O(n^2),因为插入时需要移动插入位置之后到插入元素源位置的所有元素
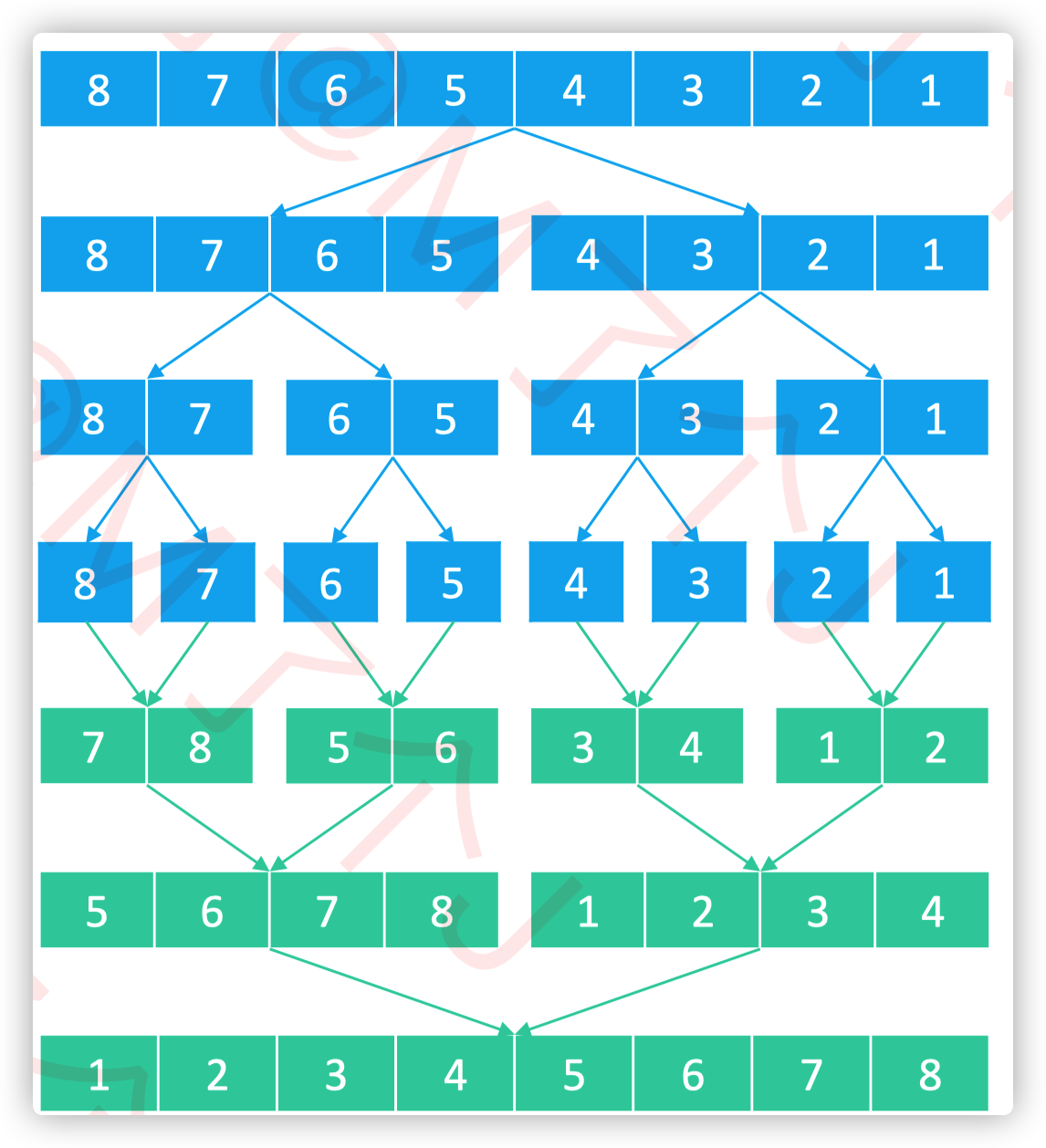
归并排序
将数组不断分为左右两部分,直到每个分数组元素只有一个
对相邻的分数组进行合并,合并后的数组应是有序的
重复2,直到整个数组有序
不断地将当前序列平均分割成2个子序列 ✓ 直到不能再分割(序列中只剩1个元素)
不断地将2个子序列合并成一个有序序列 ✓ 直到最终只剩下1个有序序列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 @SuppressWarnings({"unchecked"}) public class MergeSort <E extends Comparable <E >> extends Sort <E > private E[] leftArray;@Override protected void sort () new Comparable[array.length >> 1 ];0 , array.length);private void sort (int begin, int end) if (end - begin < 2 ) {return ;int mid = (begin + end) >> 1 ;private void merge (int begin, int mid, int end) int li = 0 , le = mid - begin;int ri = mid, re = end;int ai = begin;for (int i = li; i < le; i++) {while (li < le) {if (ri < re && cmp(array[ri], leftArray[li]) < 0 ) {else {
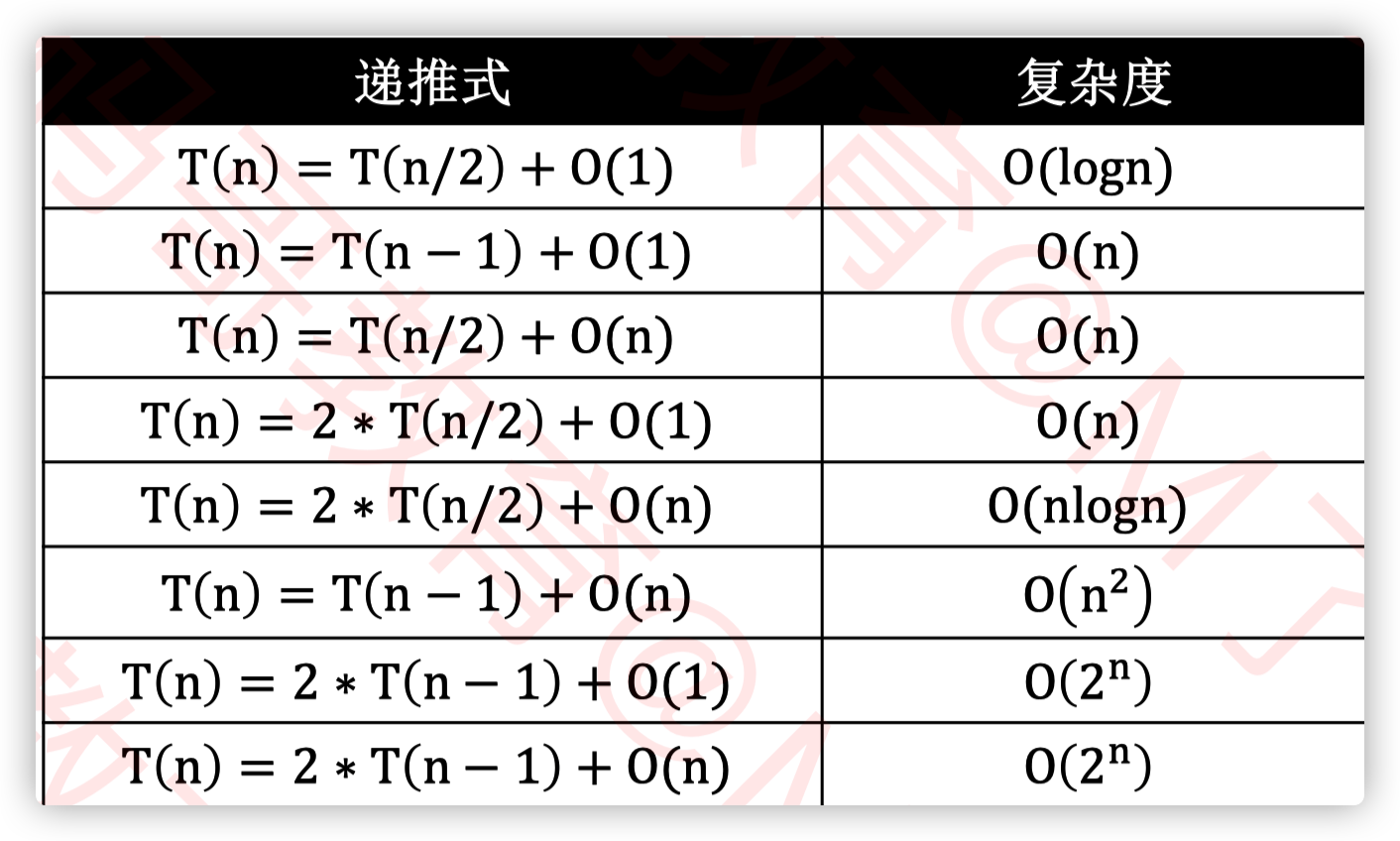
对于归并排序这类有递归调用的算法很难直观的看出时间复杂度,这时候就需要使用递推法来求啦
递推法求时间复杂度
常见递推式与复杂度 快速排序
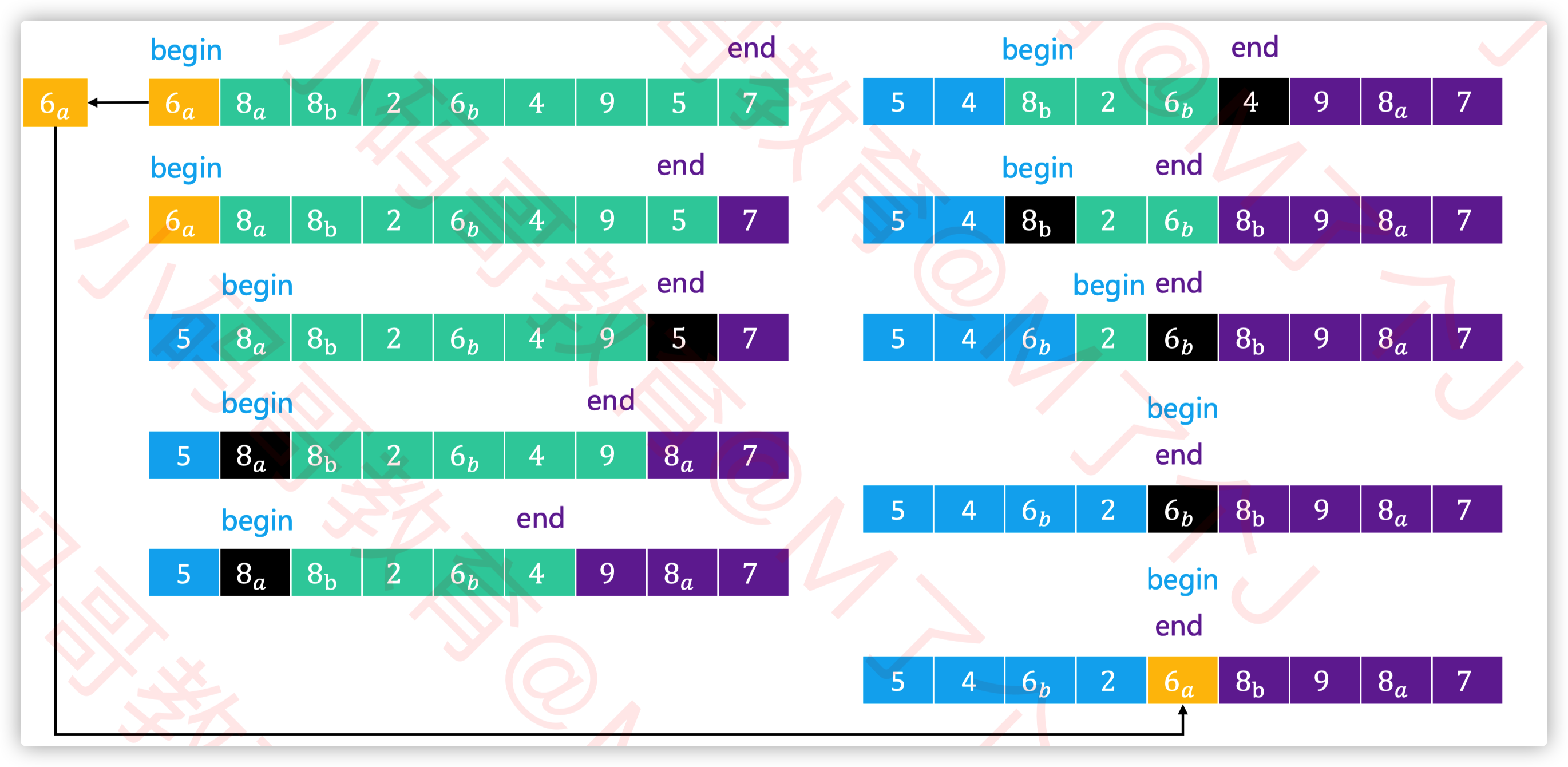
选择一个轴点元素
根据轴点将数组分为两部分,大于轴点的部分和小于轴点的部分
对于这两部分重复1、2,直到两部分元素个数都为1,排序完成
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 public class QuickSort <E extends Comparable <E >> extends Sort <E > @Override protected void sort () 0 , array.length);private void sort (int begin, int end) if (end - begin < 2 ) {return ;int mid = pivotIndex(begin, end);1 , end);private int pivotIndex (int begin, int end) int ) Math.random() * (end - begin));while (begin < end) {while (begin < end) {if (cmp(pivot, array[end]) < 0 ) {else {break ;while (begin < end) {if (cmp(pivot, array[begin]) > 0 ) {else {break ;return begin;
最好
最坏
平均
额外空间复杂度
In-place
稳定性
O(nlogn)
O(n^2)
O(logn)
O(logn)
√
×
这么写判断就会导致分割非常不平衡,时间复杂度O(n^2)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 while (begin < end) {if (cmp(pivot, array[end]) <= 0 ) {else {break ;while (begin < end) {if (cmp(pivot, array[begin]) >= 0 ) {else {break ;
为了降低最坏情况的出现概率,一般采取的做法是 随机选择轴点元素
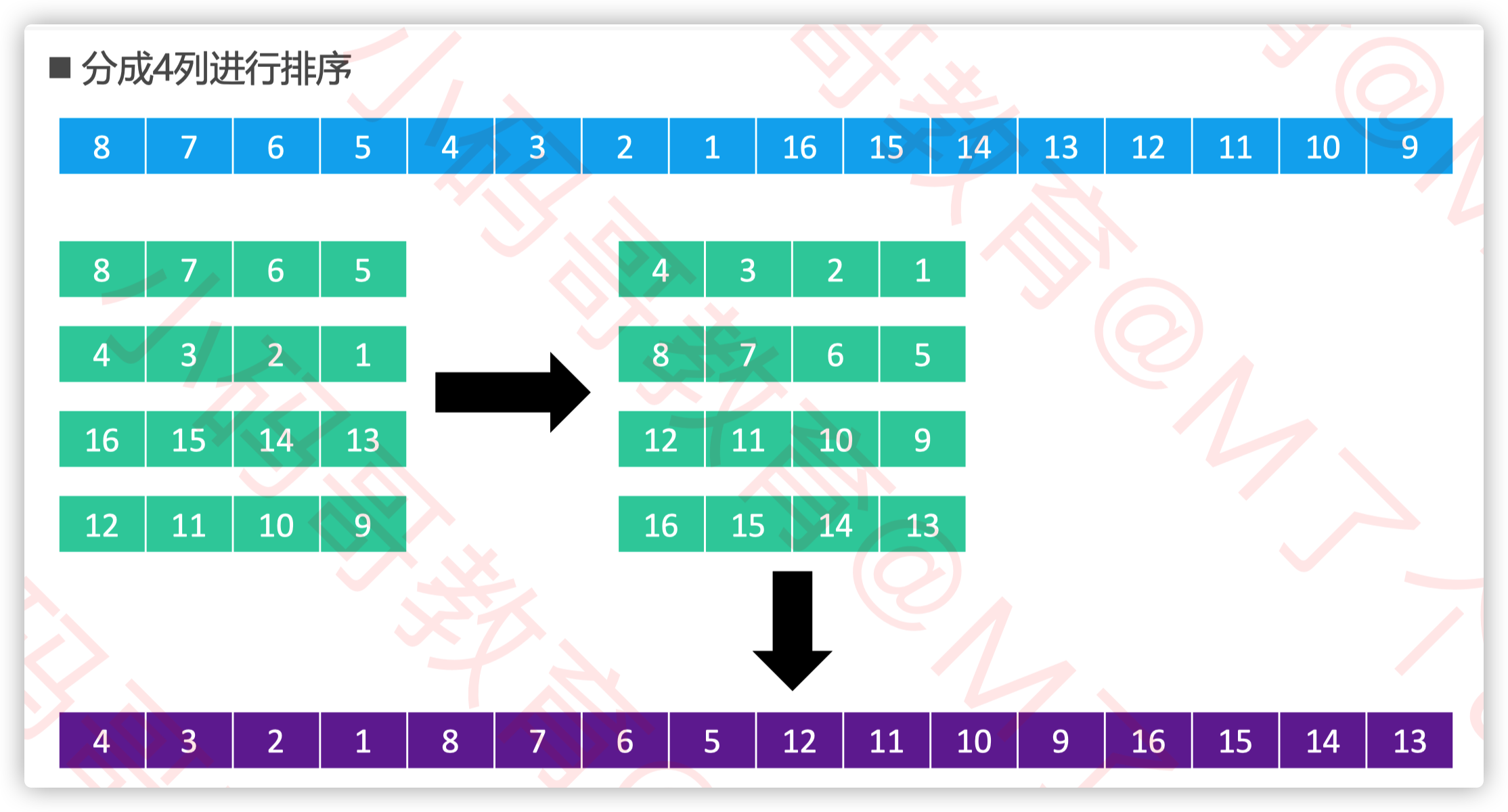
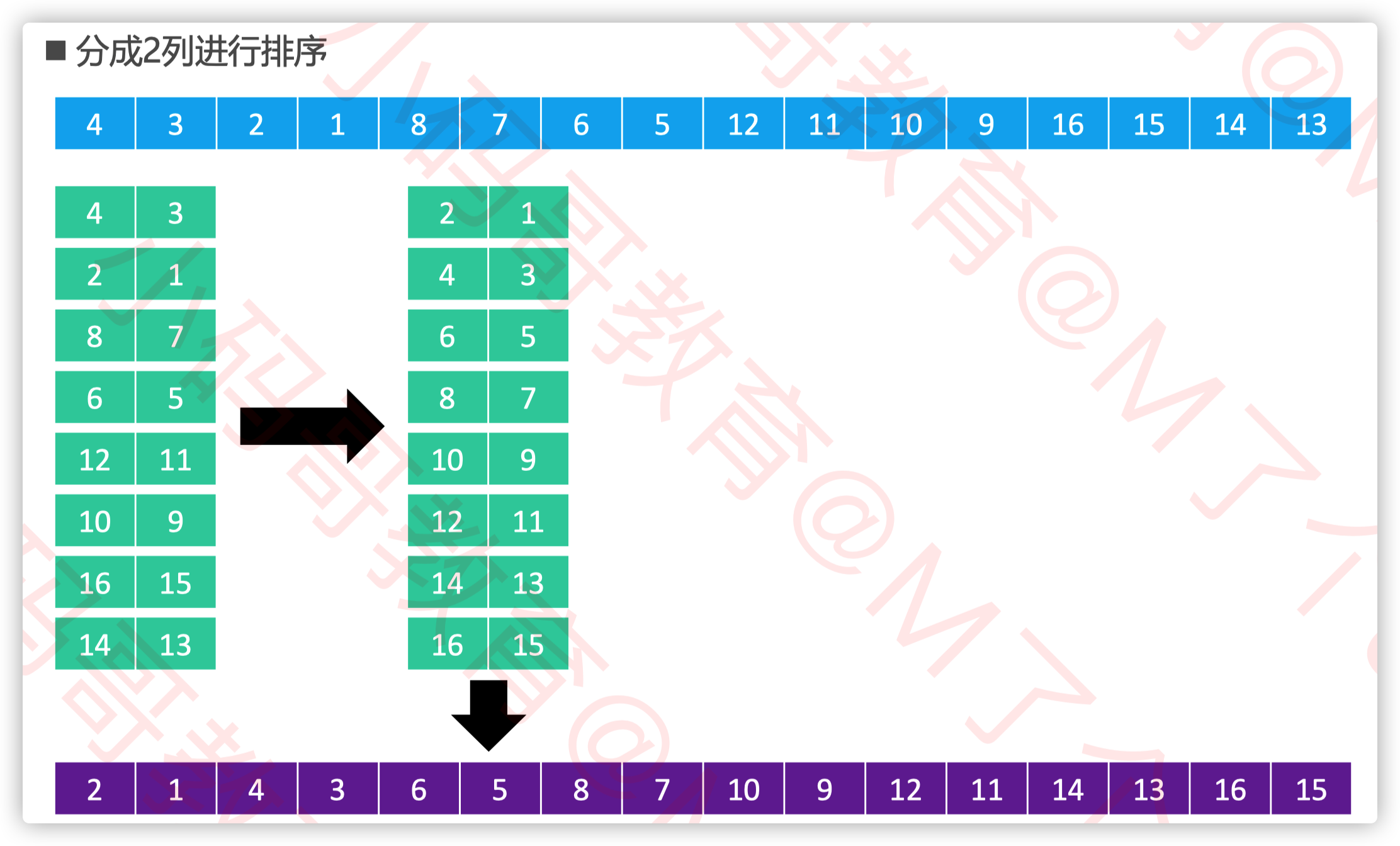
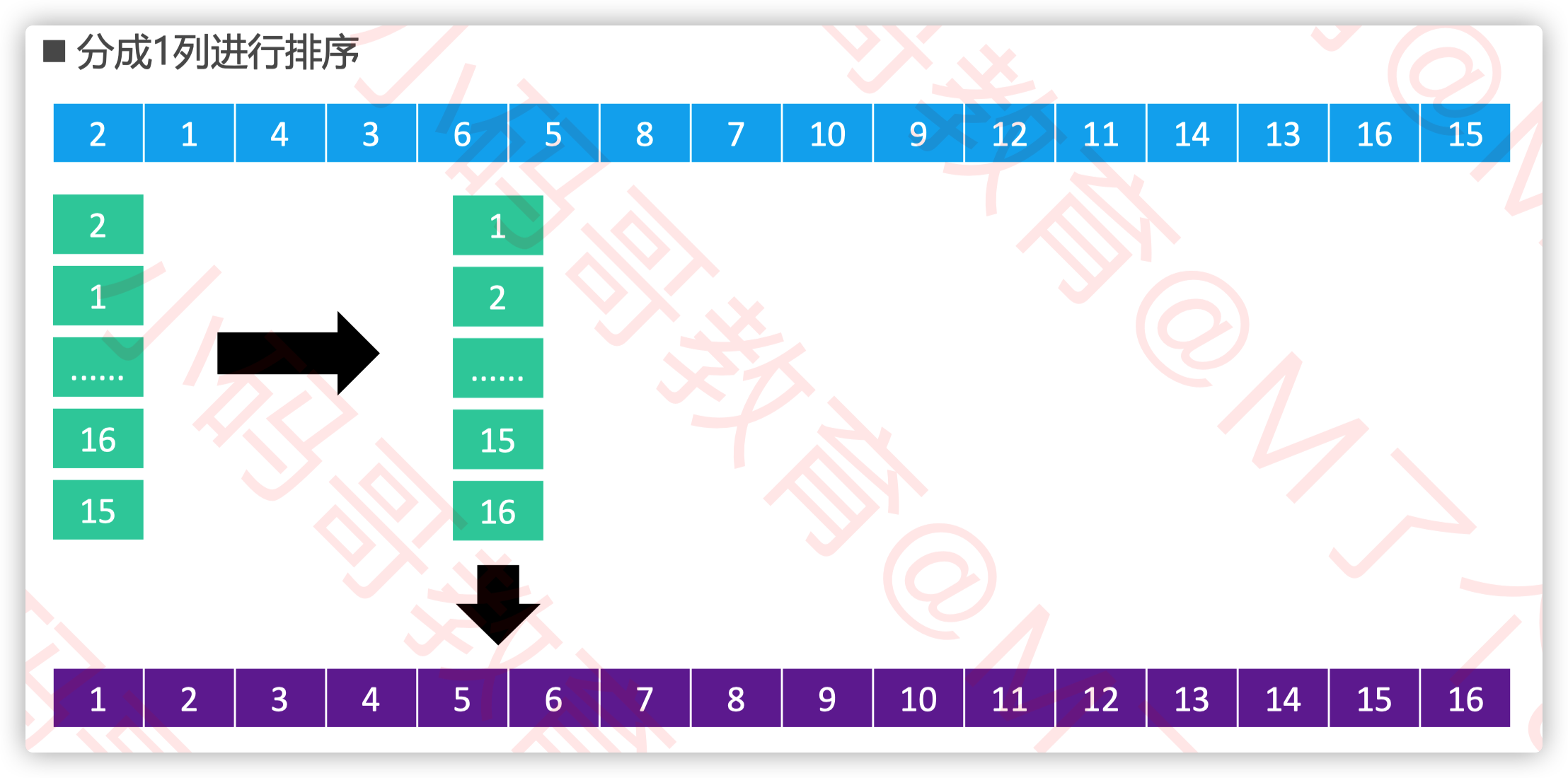
希尔排序
希尔排序把序列看作是一个矩阵,分成 𝑚 列
对每一列进行排序(用插入排序)
m从某个整数逐渐减为1
当 𝑚 为1时,整个序列将完全有序
因此,希尔排序也被称为递减增量排序(Diminishing Increment Sort)
矩阵的列数取决于步长序列(step sequence) 比如,如果步长序列为{1,5,19,41,109,…},就代表依次分成109列、41列、19列、5列、1列进行排序
不同的步长序列,执行效率也不同
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 public class ShellSort <E extends Comparable <E >> extends Sort <E > private List<Integer> stepSequence;@Override protected void sort () for (Integer step : stepSequence) {private List<Integer> shellStepSequence () new ArrayList<>();int step = array.length;while ((step >>= 1 ) > 0 ) {return stepSequence;private void sort (int step) for (int col = 0 ; col < step; col++) {for (int begin = col + step; begin < array.length; begin += step) {int cur = begin;while (cur > col && cmp(cur, cur - step) < 0 ) {
最好
最坏
平均
额外空间复杂度
In-place
稳定性
O(n)
O(n^2)
?
O(1)
√
×
最好情况是步长序列只有1,且序列几乎有序,这时时间复杂度最低
希尔排序意图减少逆序对
时间复杂度依赖于步长序列
非比较的排序
接下来介绍的几种排序算法属于空间换时间,有些时间复杂度可能比O(nlogn)更低
计数排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 public class CountingSort extends Sort <Integer > @Override protected void sort () int max = array[0 ];for (int i = 1 ; i < array.length; i++) {if (array[i] > max) {int [] counts = new int [1 + max];for (int i = 0 ; i < array.length; i++) {int index = 0 ;for (int i = 1 ; i < counts.length; i++) {while (counts[i]-- >0 ){
这是一种简单的计数排序,看得出来如果排序元素范围较大,会非常浪费空间
显然也无法对负数进行排序
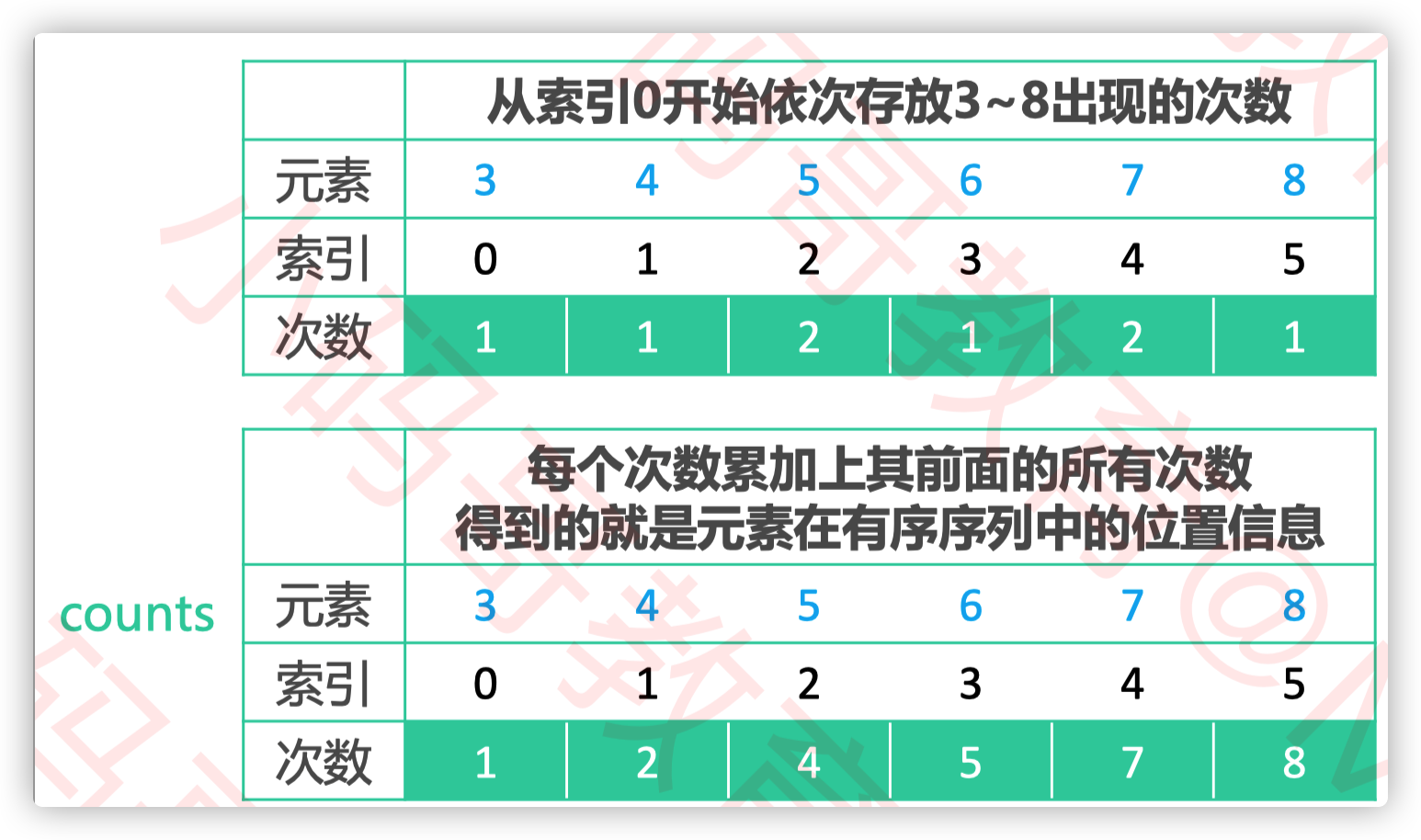
现在我们有一个待排序数组array
一个统计数组counts
假设array中的最小值是 min
array中的元素 k 对应的 counts 索引是 k – min
array中的元素 k 在有序序列中的索引 counts[k – min] – p
p 代表着是倒数第几个 k
举个例子
比如元素 8 在有序序列中的索引 counts[8 – 3] – 1,结果为 7
倒数第 1 个元素 7 在有序序列中的索引 counts[7 – 3] – 1,结果为 6
倒数第 2 个元素 7 在有序序列中的索引 counts[7 – 3] – 2,结果为 5
这样,我们就可以直接遍历源数组,根据counts数组里的信息计算出排序后数组中的位置
由于需要遍历原数组,所以使用一个新的数组来存放
最好
最坏
平均
额外空间复杂度
In-place
稳定性
O(n+k)
O(n+k)
O(n+k)
O(n+k)
×
√
Tips: 如果最后把值赋回去可不算就地排序hh,另外由于不是比较排序,所以讨论最好最坏没什么意义都一样。
也可以对自定义对象排序,前提是根据整数类型进行排序
讲完了计数排序,让我们来看看基于计数排序的另个整数排序算法^受限更大奥
基数排序
基数排序非常适合用于整数排序(尤其是非负整数:依次对个位数、十位数、百位数、千位数、万位数…进行排序(从低位到高位)
个位数、十位数、百位数的取值范围都是固定的0~9,可以使用计数排序对它们进行排序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 public class RadixSort extends Sort <Integer > @Override protected void sort () int max = array[0 ];for (int i = 1 ;i<array.length;i++){if (array[i]>max){for (int divider = 1 ; divider <= max; divider*=10 ) {protected void countingSort (int divider) int [] counts = new int [10 ];for (int i = 0 ; i < array.length; i++) {10 ]++;for (int i = 1 ; i < counts.length; i++) {1 ];int [] newArray = new int [array.length];for (int i = array.length - 1 ; i >= 0 ; i--) {10 ]] = array[i];for (int i = 0 ; i < array.length; i++) {
桶排序
创建一定数量的桶(比如用数组、链表作为桶)
按照一定的规则(不同类型的数据,规则不同),将序列中的元素均匀分配到对应的桶
分别对每个桶进行单独排序
将所有非空桶的元素合并成有序序列
因为桶排序并没有统一的分配规则,所以也没有统一的实现
这里以索引=元素值*元素个数实现一个桶排序
时间复杂度
平均
额外空间复杂度
In-place
稳定性
O ( n + n ∗ lo g n − n ∗ lo g m )
O(n+k)
O ( n + m )
×
√
性能测试
讲了这么多,还是拿实际测试看看各种排序的性能吧
对于所有排序,继承自一个抽象类,包含性能测试方法
对于稳定性是根据对于自定对象排序,观察非排序字段是否有序来判断,因此有些排序不适用而直接返回true
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 public abstract class Sort <E extends Comparable <E >> implements Comparable <Sort <E >> protected E[] array;private int cmpCount = 0 ;private static final int MINCAPACITY = 2 ;private int swapCount = 0 ;private long time;private DecimalFormat fmt = new DecimalFormat("#.00" );protected abstract void sort () public void sort (E[] array) if (array == null || array.length < MINCAPACITY) {return ;this .array = array;protected int cmp (int a, int b) return array[a].compareTo(array[b]);protected int cmp (E a, E b) return a.compareTo(b);protected void swap (int a, int b) private String numberString (int number) if (number < 10000 ) {return "" + number;if (number < 100000000 ) {return fmt.format(number / 10000.0 ) + "万" ;return fmt.format(number / 100000000.0 ) + "亿" ;@Override public String toString () "耗时:" + (time / 1000.0 ) + "s(" + time + "ms)" ;"比较:" + numberString(cmpCount);"交换:" + numberString(swapCount);"稳定性:" + isStable();return "【" + getClass().getSimpleName() + "】\n" " \t" " \t" "\t " "\n" "------------------------------------------------------------------" ;@Override public int compareTo (Sort o) int result = (int ) (this .time - o.time);if (result != 0 ) {return result;this .cmpCount - o.cmpCount;if (result != 0 ) {return result;return this .swapCount - o.swapCount;private boolean isStable () if (this instanceof RadixSort) return true ;if (this instanceof CountingSort) return true ;if (this instanceof CountingSort2) return true ;if (this instanceof ShellSort) return false ;new Student[20 ];for (int i = 0 ; i < students.length; i++) {new Student(i * 10 , 10 );for (int i = 1 ; i < students.length; i++) {int score = students[i].score;int prevScore = students[i - 1 ].score;if (score != prevScore + 10 ) {return false ;return true ;
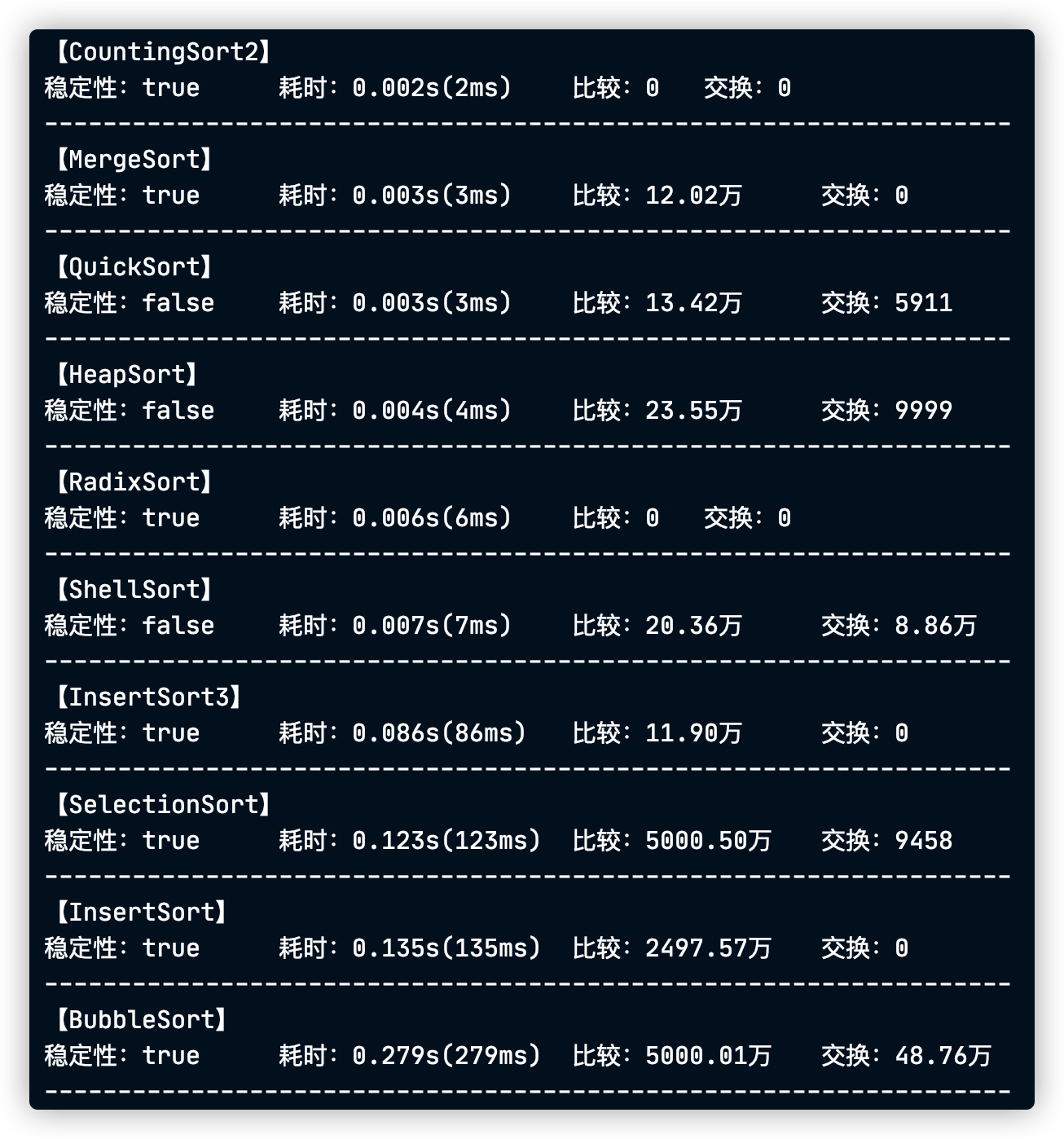
在10000个整数数据情况下,所有排序的时间都可以接受,但可以看出来几个非logn级别的比较排序明显慢了许多
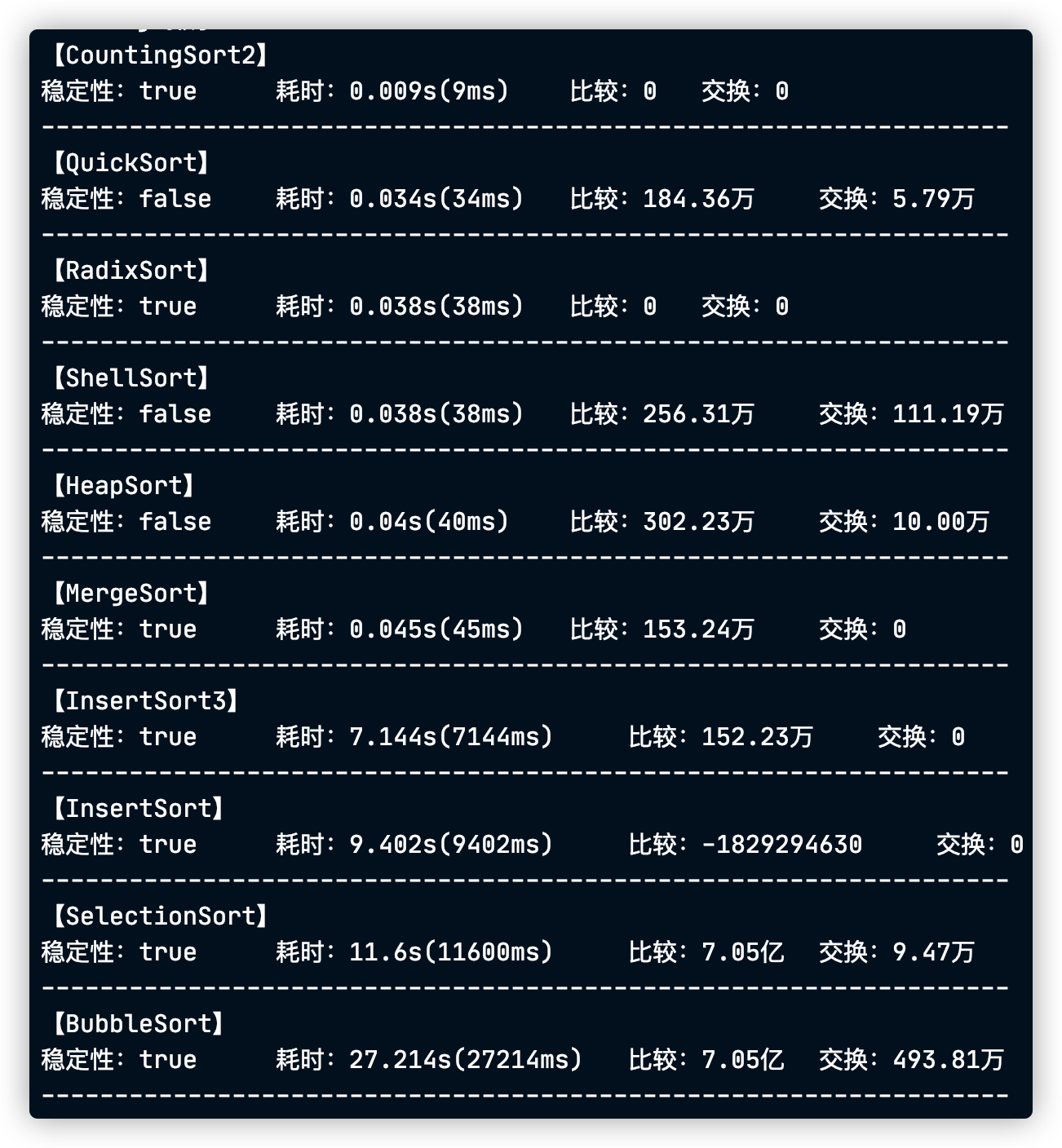
当数据规模上升到10_0000,冒泡选择和插入这些非logn级别的排序已经很吃力了,所以下一个数据规模我不会带上他们了…
插入排序比较次数都溢出了…

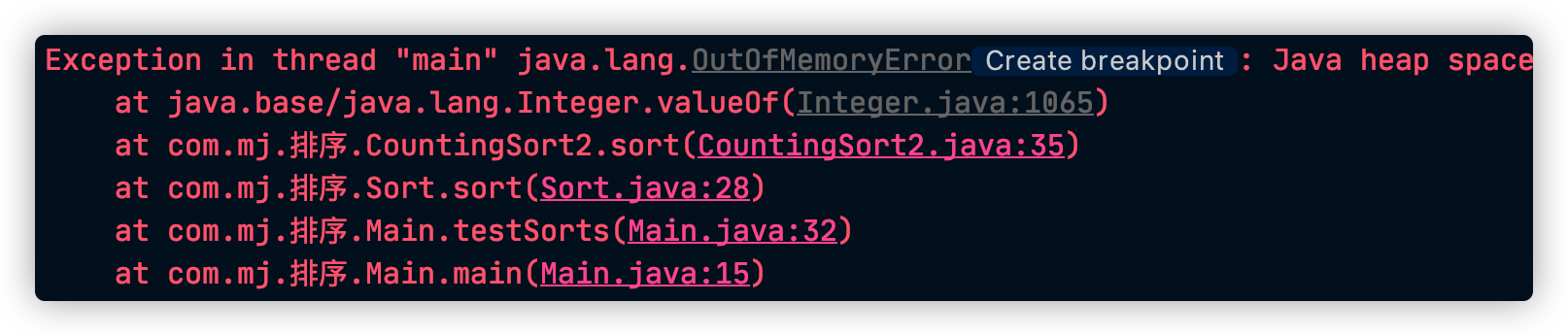
剩下的都是很能打的,不是logn级别的比较就是非比较拿空间换时间的,下次我们直接上1亿
希尔排序性能应该更好一点…可能是因为使用了没优化的插入排序
😃
对于这种级别的数据,想要在可以接受的时间内排序,就需要进行并行排序了。或者你内存够大!
到此为止常见的排序已经有所了解了,实际上这些排序算法基本来自上个世纪,我们大多数时候是在前人的基础上用这些算法解决问题。